�ܺ��������ͣ�����ͬ�����������Ultra 200ϵ����

�����ţ������ţ���һ��������ˡ��Դ�12�����Alder Lakeƽ̨����CPU�칹��������������ҡ������ѻ���ý������ҵ����˼��Ӣ�ض������ͨ���������½�һ���ı�PC��ҵ��������ChatGPT��Stable Diffusion�����LLM/AI�˳���AIPC��һ����Ҳ��һ�α����ǹ㷺���ۡ���Ϊ��������ľ�ͷ��Ӣ�ض��������������ij����Ŀ��Ultra������֮��һ�ν�AIPC�����������������Ƴ��˵ڶ������Ultraϵ�д�����������Arrow Lake����������õ���Arrow Lake��������CPU������������������ƽ̨�����������ΰɡ�
�½ӿڵdz���
���Ultra 200ϵ��������ϵ�����������Dz�����ȫ�µ�LGA 1851�ӿڣ���Ҳ��ζ���û�����Ҫ���������µ�Intel 800ϵоƬ��������ʹ����CPU��

������Arrow Lake��Raptor Lake Refresh�������ĶԱ�ͼ�����ǿ��Կ�����������������IHS��ƿ���˵��ʮ�����ƣ�������������ֲ�֮ͬ�����û����������ζ�ţ�LGA 1851ƽ̨���û����Լ���ʹ�����е�LGA 1700ƽ̨ɢ�������������ã���ô˵����һ�����¡�

���������棬LGA 1851�ӿ�������ɫ���Ǹ���Ĵ��㣬��δ�����Ų��Ѿ��൱�ӽ�������Ե������ֻ��һ���ȱ�ڣ��ڷ�������ϸ���һ����
����ƽ̨

���������õ�����ȫ�µ�ƽ̨���磬��������Ҳ�ǿ���������ʹ����ͼ��ʾ�����þ���������չʾIntel���´�����ƽ̨��ǿ�����ܱ�����ս����������Arrow Lake��һ����Ը��µ�CPUƽ̨��������β��������µ�Windows 11 24H2�汾����ϵͳ�����������ܡ���Ϸ�����빤��վ���ܲ��ԡ���Ҫע����ǣ�����Windows 11 24H2ǿ�ƿ����˻������⻯�İ�ȫ�������ڴ���������������Ӱ�����ܱ��ֵİ�ȫ�Թ��ܣ������ڲ���ǰ�ֶ��ر������ǡ�����֮�⣬�ں��Բ��Ի��ڣ����ǻ���������������CPU����ͬ���ܹ����Ե�Intel Arc A770 16GB Limited Edition�Կ����жԱȲ��ԡ�

������δ�����Ultra 200ϵ������ʹ�õ��������ǵ�MEG Z890 ACE���塣��Ϊ��Intel�����Ʒ���е��콢��Ʒ������� ACE �ijߴ��ȥ��� EATX �������˱��� ATX �ߴ磬���������˻�������ԣ�ͬʱ��Ȼ�����콢������ϣ��������������˿��Ultra 200ϵоƬ�ĸ��������ԣ�����˵��չʾ�����ƽ̨�IJ���֮ѡ�ˡ�

���ڴ���i9 14900K���Ե�LGA 1700ƽ̨�����ϣ�����Ҳѡ����ͬ�������ǵ�MPG Z790 EDGE TI MAX WIFI���������壬�����������Կ���ƪ���¡������Լ۱ȵĸ߶����������18��߹�硢���7800MT/s XMP��DDR5�ڴ�����PCIe 5.0������չλ���ܹ��������ӿ��i9 14900K��IntelĬ��Ԥ���µ����ܱ��֡�



P��E��ȫ������
��Ϊ����˵ĵ�һ�����Ultra������ƽ̨��Arrow Lake�ں��Ĺ�ģ���ͺ��϶����˲�С�ĸĽ��������������ľ��dz������˳��̹߳��ܡ��������2002���Pentium 4 Northwoodƽ̨�����û���һ�μ��棬�����Atom�����Լ���̥�ü��������montϵ��Ч����֮����������Ѽ������ж��г��֣������Ǹ��ݶ�λ�ڲ���SKU�йرն��ѡ�����Arrow Lakeƽ̨�ϣ����̹߳������DZ�Ӳ��ȥ�������ײ����ټ���
���ǵ����̼߳�����������������������ϵͳ���ø����CPU���ģ�������ͨ�û����ճ�����Ӧ�ó����д����������������ޣ���֮���̼߳������������ӵ�CPU�̵߳��Ȼ��ƴ����ĸ���Ӱ�죬�ڱ�����Alder Lake�������洦�������������Ѿ�������ǰ�����Ƴ���һ���ƶ�ʵ�ʷ�ӳ��Ӧ���е����ܱ��ִ���������Ӱ����ѳƵ��ϸ��档�����������ǽ������IJ���������Կ������ڳ�����������Ӧ���У���һ�����Ultraƽ̨���������14900K�������������������Ȼ�ˣ����ڸ��ز��жȸ��ߡ��ܹ���Ч���ó��̼߳������ƵĹ���վ/������Ӧ��ƽ̨������Xeonƽ̨���ԣ����̹߳�����Ȼ�DZ��ֿ����ġ�
������ƽ̨��P�˺�E�˼ܹ�Ҳ˫˫�õ���������Lunar Lakeһ���ֱ������Lion Cove P����Skymont E�ˡ���������װ��Lunar Lake���Ѿ����������ܺı��ϵ����ƣ��������Ĺ�ģ�빦�����ƶ���Ϊ���ɵ������ƽ̨Ҳ��Ȼ���������һ����Բο����ǽ��������еIJ��ԡ�
���˺��ļܹ�֮�⣬����Ӣ�ض����Ultra 200ϵƽ̨�ڻ������Ľ�Ҳ��Ϊ����������ȫCPU���Ĺ��������36MB L3 Cache��ÿ����Ч�˼�Ⱥ��4MB L2 Cache֮�⣬����ÿ�����ܺ��ĵ�L2 Cache��������3MB������ζ����Ultra 9 285V�������ϣ�����ȫϵͳ��L2 Cache���Ѿ�������32MB���������Ѿ�����������һЩ��������ȫpackage�����������ڸ������е���ϷӦ���������ܹ������൱�ɹ۵�����������
����CPU�ܹ�֮�⣬����Ӣ�ض����Ultra 200ϵƽ̨Ҳ�״��ڴ�ͳ���洦�������������Ƚ���Foveros 3D��װ���գ��ܹ������ò�ͬ�Ƴ̹��������оƬ��Ϊһ�塣�����̽����CPUģ����IOģ��ͨ��PCB���װ��һ����Ʒ�еķ�����ͬ��Foveros 3D�����ܹ������������ճ�Ʒ����Ʒ��֮�⣬�ù���Ҳ������Ʒ����������˵���Բ�ͬ���͵ĸ��ض��岻ͬ��оƬ�ܹ������ͻ����ӳ٣�������������ƽ̨��������ܱ��֡�������ҵ����Sapphire Rapids Xeonƽ̨֮�⣬Foveros 3D��װ����Ҳ���ᱡ���д����ʵ�Meteor Lake/Lunar Lake�������Ultraƽ̨�з��ⷢ�ȡ�ͬʱ�����г������ϣ�Foveros 3D��װ����Ҳ�ܹ����������¼����Ľ���Ч�ʣ���Lion Cove��Skymont���ֺ������ƶ�������һ���º��������˷�ī�dz������ڱ��η�����Ӣ�ض����Ultra 200ϵ����ƽ̨�ϣ����ǿ�������CPU��װ��������ģ�顢IOģ�顢GPUģ���SOCģ�飬ͨ������ģ�黥�����ӣ�����һ�����ģ������ƽ��������
ͬʱ����Ƶ�ʿ��ƻ��ƣ��Լ��ɴ������ij�Ƶ�淨�ϣ�����Arrow Lakeƽ̨Ҳ�����˴����ĸĽ�����������ʱ���ܹ���16.67MHz�IJ������е�Ƶ�����ܹ���ģ��Ϊ������λ���о��ܵ�Ƶ�������Դ������������̬�ȷ���������������ܹ��ó�Ƶ�������dz������Ƶ�ʡ�

��Ȼ�ˣ����������ۣ�ʵ����ʵ����������Intel Default Settings �C ExtremeԤ���½�����30���ӵ�FPU�������ԣ��Ա����Ŵ��������ĸ���ͬģʽ�µ�Ƶ���빦�ı��֡����Կ�����Ultra 5 245K��Ultra 9 285K��P��ȫ��Ƶ�ʾ���ͻ��5GHz��E��Ƶ��Ҳͻ����4.5GHz��Ȼ�����Ŀ��Ʊ���ȴ��Ϊ��ɫ��ͬʱ�����ǿ������رճ��̺߳��i9 14900K�ڸò�����ֻ�õ���8W�Ĺ��Ľ��ͣ�Ϊ��һ��ƽ̨ӭ���˵�һ�����ź졣

���������ϣ�������3DMark CPU Profile��������Ŵ���������Ϸ���ܽ��п��ˡ����Կ��������������Ϊ��ģ�����ߵ���Ultra 5 245K��ȫ�̲߳����а�������֮�⣬��ÿ��������Ŀ����Ultra 200ϵƽ̨�ĵ÷ֶ����������ϾɵĿ��i9 14900K�����ּ�Ϊ��ɫ��

��������ʵ����ϷӦ�õ�������У�����Ҳ���������Ƶ����ݱ��֡�

����CPU-Z���У����ǿ���i9 14900K�ڼ�������������Ȼ��һ�������ƣ���鹦�������ߵ�Ƶ�ʱ궨����һ���ں���IJ�����Ҳ�ܿ�����
�ټ��ˣ����е�DDR4
���ڴ���������棬Arrow Lakeƽ̨���������˶�DDR4��̬��֧�֣�ΪDDR4��һ��2014��Haswell-E��������һֱ���г��Ϻ��绽����ڴ���̬�����������г�������������ʽ��������ֹ������Ȼ������DDR5�ڴ����Ÿ��ҹ�Ӧ�̲������£��ڼ۸����Ѿ�ʮ���������DDR5����Ҳ�ܹ���Ч���ڴ��������ƣ��ṩ���ɿ��Ҹ����ܵIJ�Ʒ����Ҳ����ʷ��չ�ı�Ȼ���ơ���֮��Intel���Arrow Lakeƽ̨�ṩ��6400MT�Ĺٷ��궨����֧��CUDIMM��CSODIMM��ECC���Ƚ�����������ζ�Ŷ��ںܴ�һ�����û������������Ƴ�Ƶ������Ʒ�������û���˵��ʹ��JEDECƵ�ʱ���Ҳ�ܹ�����൱�ɹ۵��ڴ����ܣ�����ҵ��ңң���ȡ�ͬʱ�������ڴ��������������Ҳ��ζ�ż�ʹ�û����ڴ�Ƶ���Ƹߵ�8000MT��ϵͳҲ��Ȼ�ܹ���Gear 2ģʽ������������Intel�Ĺ�����Ա��ý����Ͻ���һƵ���������㡱������ʾӢ�ض����Ultra 200ϵƽ̨���ܹ���һ��ѹե�ڴ�Ƶ�ʡ�����˵�������ڴ泬Ƶ��������˵������ƽ̨�ܹ������൱��Ȥ��ʹ�����顣
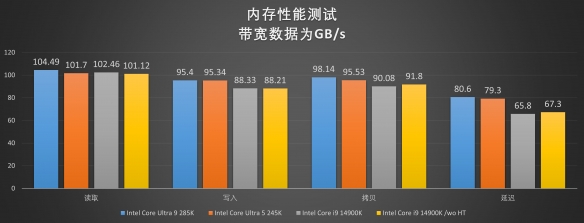
��Ȼ�����Dz���ʹ�õ�����Ȼһ������Ӱ�۵�DDR5 6800MT CL36����������Ҳ��Ŀǰ�൱�������ڴ�Ƶ��֮һ����AIDA64���ڻ������ܲ����У������ܹ���ϵͳ���ڻ������ܽ��п��졣��ͬ����6800C36��Ƶ���£� ���Dz���������ƽ̨���ڴ����ܣ����Ultra 200ϵ�Ĵ�������������һ��Raptor Lake��������ֻ���ӳٷ�����ѷһ�
�����PCIe

��������ƽ̨���������CPUΪ�������ǡ�����AIC������Ϊ�����Ĵ�ͳ��ʽ���һ���PCIe���ߵ�NVMe��̬Ӳ�̡������������Χ���������������߲�Ʒ�е��ռ�Ҳ�Դ�����ƽ̨��PCIe��չ����������൱��Ҫ����Intel����11��Rocket Lakeƽ̨���Ѿ���CPUֱ����PCIeͨ����������20��PCIe 4.0���ߣ�֧��һ��M.2��̬Ӳ����һ����ѪPCIe x16�Կ���ֱ����������һ��Arrow Lake�������ϣ�Intel����������������ֱ����PCIe 5.0���ߣ�����PCH�ṩ��ͨ������һ���Ƹ���ϵͳ����չ������

�����PCIeͨ�������豸�������ṩ������������巽����Ϊ�����ߴ�����������ѡ�����磬�������ʹ�õ�MSI MEG Z890 ACE�����ͬʱ֧������PCIe 5.0*8������չ�� ��������x4 M.2Ӳ��ͬʱֱ��CPU����������һ��Ӳ�̻���5.0*4�ij������������֮ǰ�������м�����������Ȼ�ˣ����ǵ�PCIe 5.0*8�Ĺ��ʹ����RTX 4090�������콢��GPU��������ɴ���ƿ���������IJ�ֶ���һ��������Ϸ��ҵ�������˵�൱��������������������ʽ��������Ҳͬ������������Щͨ���ṩ�����GPU����������̫�����������п����豸����Ч����ֱ��CPUͨ���ĸ����ӳ�ʵ�ָ�����Ҷ��������ղ�Ʒ������
������ʿ��

������������ƶ�ƽ̨��Lunar Lake�����صĵڶ���Intel Xe Battlemage����ƾ���ŵڶ���Xe���ı���������ǿ��������Lunar Lakeƽ̨��������ƴ����������ܺı����������������ڣ���Arrow Lakeƽ̨��Ȼ���ػ�����һ��Alchemist Xe-LPG GPU�ĺ��Է�������Ȼ�ˣ���Ϊ�����������������A770 Limited Edition��������Լ�PC��ʹ������GPU��Ϊ�������û����ԣ����߶�Alchemist���Intel�ڸ�����GPU������Υ30������㻹��ʮ������ģ����������GPU�ܹ��������ĶԸ�����Ƶ��ʽ��Ӳ�����������Ҳ�ܹ�Ϊ��ý���������û�������û�����ʮ��������������
�ڼܹ��ϣ�Ӣ�ض����Ultra 200ϵƽ̨��Xe GPU����Xe-LPGͼ�μܹ����죬���֧��4��Xe���ģ����ܹ�ģ��Զ�����ƶ���ƽ̨�������ǵ���һƽ̨һ����������Կ�����֧��DP4a AI���١�Xeʸ�������ý���������������ʵ�ֵ����8TOPS��AI�������Եü�Ϊ�����ˡ����磬���GPU֧���������µ�8K XABC����������ܹ�Ϊ�������������ݵĹ����ߴ����൱�ɹ۵�����������

��֮���������������ܡ�����ʱ�����ޣ�������ξ�ֻ��������3Dmarkͼ�β��ԡ���3Dmark���������GPU������������У������ź����ܳ����൱�ɹ۵ijɼ��������ǶԱ���һ��i9 14900K��UHD 770���Ի��������ڶ�Ӧ��λ�����в����Radeon 610M���Զ���������������������������Lunar Lake�����ƶ�����ƽ̨�д��صĴ��ģ������Ȼ����ȣ���֧�����4����ʾ��������Ҳ��Ȼ���˹�Ŀ���
̨ʽ��Ҳ��NPU
������AI PC��һ�������˵��һ�����š�ͨ����SoC�м���NPU��ջ��һЩAIӦ�ñ��ػ����𣬲����ܹ���������ϵͳ�������ܺı��֣����ܹ�ΪOEM��ISV�ṩ�ɿ��Ŀ���ƽ̨��������Ҳ�Ƴ���Copliot PC�����ƽ�AIPC���ռ���������Intel�Լҵ�Meteor Lake��Lunar Lake����������PhoenixΪ������һƱAI PCƽ̨���������൱�����ܵ�NPU��������Arrow Lake�����г��ϵ�һ�������NPU��x86 MSDTƽ̨������iGPU��CPU������������ܹ�ʵ��36TOPS��ƽ̨�������ٴ�����һ����A770�����ĸ����ܶ����Կ��������AI������ʮ�ֿɹ��ˡ�

������90���GPU�г�һ���ٻ���ŵ�NPU�г��У�Intel��NPU��Ʒƾ���Ÿ����Ƶ���������ջ�Լ�oneAPI������ͳһ���������ܹ��ÿ����ߺ��û��ڲ�ͬ���͵��豸��ʹ��ͬһ�״���ջ������������AI����ʵ����ص�Ч�ʡ�����ʹ��Geekbench AI�Կ��Ultra 200ϵ��������AI���ܽ����˲��ԣ����Կ����ڶ������Ultraƽ̨��AI����ȷʵ�൱�ɹۣ���������Ѫ��A770 16GB LE���������£���AIӦ�ã��������ܹ���Ч����CPU GPU NPU���칹AIӦ�ö��ԣ��ڶ������Ultra�����������͵�����һ��A770����Intel�ṩ��ͳһ��������ջҲ�ܹ�����ISV��Ч��������������˵������һ������ѭ���ĵ�·���ˡ�
��Ϸ����

����Ϸ���Ի��ڣ�����ʹ��RTX 4080 SUPER�Կ�����1080P��ͻ����½�����Ϸ���ܲ����Ծ����ܸ�CPU��ѹ����
������CPU�����е�CS2��Ŀǰ��CS2����ͨ��������ṩ��fps_benchmark��ͼ���� ���ܲ��ԣ��������CPU/�ڴ����е���Ϸ�У����ǿ��Կ���Ultra 9 285K�����ܱ�����i9 14900K�������£��ڽӽ�700֡��ƽ��֡�½��������֡��������ȴʵ��ʵ�ؽ�����100W�������൱���ޡ�

�������ջ���14�����У���������ͻ��ʡ�100% FSR���رտɱ�ֱ��ʣ����������˶�������Ч���в��ԡ��������Ϸ�У����Ultra 200ϵƽ̨����˵��ȫ��ʤ����������ƽ��֡���ǹ��ı��ֶ����������ƣ������൱��ɫ��

���������2077����ִ�3A��Ϸ�У�Ultra 9 285K�ڴ���Ϸ�����Ͼ���ѷһ����ǹ����ϵ�����ȴ��Ȼ��������������ָ�Ϊ��ɫ�ķ�����С�ŵ�Ultra 5 245K��80W�����Ĺ��ı���ȴ�������������Ϸ���ܣ�������̾��

���ں���������������5�����ġ��ڼ���ջ�ϼ�Ϊ�Ƚ��Ĵ����ϣ�����Ҳ���������Ƶ����ܱ��֣�ֻ������Ultra�������Ĺ��ı���֮�������16W����2077�����ݸ��͡�

F1 2024�������ܸ��ص�������Ϸ�п��Ultra 5 245K��һ�����ֳ������˵�ǰ�����ʵҲ��350֡��ƽ��֡��243֡��1% Low֡�����ǵ�F1 2024�����Ϸǿ�ƻ��ڹ��������У���֮�����������U5ֻ�ķ���54W���ʣ������ı���Ҳȷʵʮ�����㡣

�����CPU���ܲ�����Ϸɱ����Χ�������������һ�����Ultra 200ϵռ�ݾ������Ƶ�ս��������˵��ȫ�污ɴ��ͬʱ��i9������Ҳ���Կ����������Ϸ�ƺ��Գ��̼߳����������Ѻã����ǵ�i9 14900K�ڹرճ��߳�֮�����ܱ��ַ�����һ����������
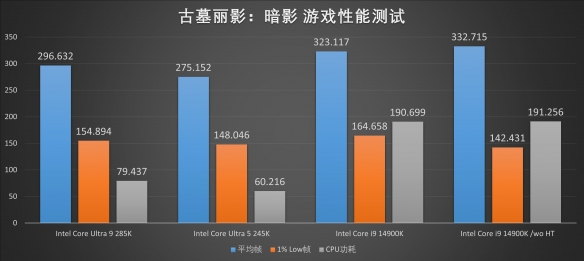
��һ�������ܲ�����Ϸ��Ĺ��Ӱ����Ӱ���棬����Ҳ������ͬ�������ơ����ǵ���������Ϸ������Եڰ�������������������Ϸ������Alder Lake�������칹���㴦������������Arrow Lake�������رճ��̼߳����Ĵ�����֧�ֲ���Ҳ��ʮ�ֺ�����ֻ�Ǿ��ܼ������������аܼ������Ƚ����ռӳ��µĿ��Ultra 200ϵƽ̨���ܺı�����Ȼһ������ij�ɫ���ھ��������Ϸ�еĹ��ı��������ܹ�ֱ�Ӱ����Ϸ�������ò������ڴ�������������ARL-HX�������ƶ�ƽ̨�����ܱ����ˡ�
����վ����
���˵Arrow Lakeƽ̨����Ϸ�����ܱ���Ϊ������ǧ����ɾ����ڵ���Intelƽ̨����ߵ㣬��ô�ڴ������������������������Ӧ���У�������ӹ���ɵ���ȫ��Ŀ���������Ǹ��̡���������ͨ����������UL Solution Procyon�������İ칫�������������Կ�ʼ���������ͨ��MS Office���ܹ���Ч�ز���ϵͳ�ڸ�ǿ�ȵ�Office�칫�����µ����ܱ��֡�


Cinebenchϵ��������Cinema4D��Ⱦ���������ǿ���CPU��3D��Ⱦ���������ܱ��ֵ����ù��ߡ����Dz������ĸ�ƽ̨��Cinebench R15��R20��R23�Լ����µ�2024�汾�е����ܱ��֡����Կ�����Cinebench���ijɼ�Ҳ������֮ǰ���Ե�3DMark CPU Profile�е����ƣ�����Ultra 5 245K��Ϊ��ģԭ���ڶ�������ϵ÷�ѷ��i9֮�⣬���Ultra 200ϵƽ̨�ڸ���Ŀ����Ȼռ�ݾ������ơ�

����������ߵ�Blender 3D��Ⱦ���У�����������Ԥ�賡����Ҳͬ�����������Ƶ�����������Ultra 9 285K���i9 14900K���������ȸߴ�30%������3D��Ⱦ��������˵����ʮ��������

������������V-Ray 6��Ⱦ���У����Ultra 9 285K������Ҳ������24.9%����������ͬ���ɹۡ�

��Ȼ������Ǵ��У�SPECworkstation���������ع�ҵ����������������ȫ��λ����ϵͳ�ڸ��ӵĹ���վӦ���µ����ܱ��֣�Ϊ�û��ṩȫ������ܽ��ۡ����Կ������ڼ���������Ŀ�У��������Ultra 200ϵƽ̨����ɫ��һ�����죬������Octave��Ⱦ���IJ�������1.98�ֵijɼ���ѷi9 14900K��2.17�֣����ֿ����С�
�ܽ�
�����Dz��Ե������Ͽ��Կ��������Ultra 200ϵƽ̨ȷʵ�Ƶ�����һ�������ķ����Ѽ������������ʹ�����Ǹ��Ƚ���3D��װ���ա���չ�����ϵ�ȫ�������������ܵ�Xe������NPU��ֻ��ע�����CPU���ܣ��������ڸ���������Ӧ���������ױȵĶ�������ܱ��ֻ�������Ϸ���������͵Ĺ��Ķ������ñ��߶�����һ���Ŀ��ƽ̨ʮ�����⡣������ǰ���ᵽ�ĸ��༼������֮�����ƽ̨������������һ��Ӣ�ض����е�δ���������ϵ��ͬʱ�����Ultra 200ϵƽ̨�൱�����ܺı��֣�����Ŀǰ����Ը�����һ���Կ��Ĵ��ԣ��ñ���ͬʱҲ����һ��HX�ƶ�ƽ̨�����ڴ���
0����Ķ�
- ˫11�Ż�����ͣ����˶�羺��ʾ�����ݴ�����
- ����Ƽ��������ζIJ���Υ������ �����ƽ������ж�
- ����9400����������40%�����λ��ʸ���ʵ!
- �źŹ�˾���ֵ綯��ȫ���ж��ܽ���ΰ�ȫ�������ػ��û����ij�
- ˫11�����ʢ����������ROG����ֵ������
- ����9400��Ϸ����ԭ���������������㡷ȫ��ֱ����֡��
- ̽Ѱ�羺�������� TEC��η��Լս�ӷ������������ܲ�
- Բ�������13/14������ȶ�������¿ɽ��������ûӰ��