重磅!Meta推出开源大模型Llama 3,性能直逼GPT-4
原标题:重磅!Meta推出开源大模型Llama 3,性能直逼GPT-4
每经编辑:杜宇
当地时间4月18日,AI 领域迎来重磅消息,Meta正式发布了人们等待已久的开源大模型Llama 3。

与此同时,Meta首席执行官扎克伯格宣布:基于最新的Llama 3模型,Meta的AI助手现在已经覆盖Instagram、WhatsApp、Facebook等全系应用,并单独开启了网站。另外还有一个图像生成器,可根据自然语言提示词生成图片。
Meta首席执行官马克·扎克伯格在一段视频中表示,该助理可以回答问题、制作动画和生成图像。

扎克伯格在 Facebook 上发帖:Big AI news today
Meta首席执行官马克·扎克伯格在视频中表示:我们相信,Meta AI现在是你可以自由使用的最智能的人工智能助手。Meta AI内置于WhatsApp、Instagram、Facebook和Messenger应用程序的搜索框中,因此用户可以轻松地提出可以通过新工具回答的问题。

扎克伯格表示,Meta 提供的生成式 AI 能力在免费产品中性能是最强大的。
在 Facebook、Instagram、WhatsApp 和 Messenger 上,用户现在可以借助 Meta AI 进行搜索,无需在应用程序之间切换:

当你浏览信息流的时候,还可以直接从帖子中向 Meta AI 询问更多信息:
图像生成器带来的玩法更加有趣,Imagine 功能带来了从文本实时创建图像。这一功能的测试版从今天开始在美国的 WhatsApp 和 Meta AI 网络体验上推出。
开始打字时,你会看到一个图像出现,每多输入几个字母,图像都会发生变化:

Meta表示,Llama 3在多个关键的基准测试中性能优于业界先进同类模型,其在代码生成等任务上实现了全面领先,能够进行复杂的推理,可以更遵循指令,能够可视化想法并解决很多微妙的问题。
Llama 3的主要亮点包括:
基于超过15T token训练,相当于Llama 2数据集的7倍还多;
支持8K长文本,改进的tokenizer具有128K token的词汇量,可实现更好的性能;
在大量重要基准中均具有最先进性能;
新能力范畴,包括增强的推理和代码能力;
训练效率比Llama 2高3倍;
带有Llama Guard 2、Code Shield和CyberSec Eval 2的新版信任和安全工具。
刚刚发布的8B和70B版本Llama 3模型已用于Meta AI助手,同时也面向开发者进行了开源,包括预训练和微调版本。
最新发布的8B和70B参数的Llama 3模型可以说是Llama 2的重大飞跃,由于预训练和后训练(Post-training)的改进,本次发布的预训练和指令微调模型是当今8B和70B参数规模中的最佳模型。与此同时,后训练过程的改进大大降低了模型出错率,进一步改善了一致性,并增加了模型响应的多样性。
Llama 3将数据和规模提升到新的高度。Meta表示,Llama 3是在两个定制的24K GPU集群上、基于超过15T token的数据上进行了训练——相当于Llama 2数据集的7倍还多,代码数据相当于Llama 2的4倍。从而产生了迄今为止最强大的Llama模型,Llama 3支持8K上下文长度,是Llama 2容量的两倍。
此外,Meta还开发了一套新的高质量人类评估数据集。该评估集包含1800个提示,涵盖12个关键用例:寻求建议、头脑风暴、分类、封闭式问答、编码、创意写作、提取、塑造角色、开放式问答、推理、重写和总结。为了防止Llama 3在此评估集上出现过度拟合,Meta表示他们自己的团队也无法访问该数据集。下图显示了针对Claude Sonnet、Mistral Medium和GPT-3.5对这些类别和提示进行人工评估的汇总结果。
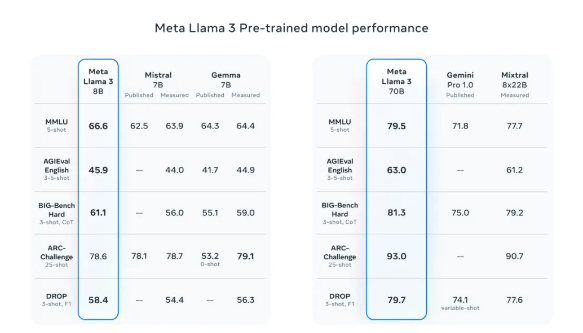
下图是 Llama 3 预训练模型和其他同等规模模型的比较,前者表现出 SOTA 水平。
为了训练最好的语言模型,管理大型、高质量的训练数据集至关重要。Meta在预训练数据上投入了大量成本。Llama 3使用超过15T的token进行了预训练,这些token都是从公开来源收集的。总体上讲,Llama 3的训练数据集是Llama 2使用的数据集的七倍多,并且包含四倍多的代码。为了为即将到来的多语言用例做好准备,超过5%的Llama 3预训练数据集由涵盖30多种语言的高质量非英语数据组成。但是,Llama 3在这些语言上的性能水平预计不会与英语相同。
为了确保Llama 3接受最高质量数据的训练,研究团队开发了一系列数据过滤pipeline,包括使用启发式过滤器(filter)、NSFW过滤器、语义重复数据删除方法和文本分类器来预测数据质量。
研究团队发现前几代Llama非常擅长识别高质量数据,因此Meta使用Llama 2为给Llama 3提供支持的文本质量分类器生成训练数据。
研究团队还进行了广泛的实验,以评估出在最终预训练数据集中不同来源数据的最佳混合方式,最终确保Llama 3在各种用例(包括日常问题、STEM、编码、历史知识等)中表现良好。
Meta表示,最大的Llama 3参数超过400B,虽然这些机型仍在训练中,但在接下来的几个月中也将陆续发布,新功能包括多模态、多语言对话能力、更长的上下文窗口以及更强的整体能力。
Meta希望Llama 3能赶上OpenAI的GPT-4。不过知情人士透露,因为研究人员尚未开始对Llama 3进行微调,所以尚未决定Llama 3是否将是多模态模型。微调是开发人员为现有模型提供额外数据的过程,以便它可以学习新信息或任务。较大的模型通常会提供更高质量的答复,而较小的模型往往会更快的提供答复。有消息称,正式版的Llama 3将会在今年7月正式推出。
Meta还宣布与Alphabet的谷歌建立新的合作伙伴关系,在助手的答复中包括实时搜索结果,作为与微软必应现有合作的补充。随着此次更新,Meta AI助手正在扩展到美国以外的十多个市场,包括澳大利亚、加拿大、新加坡、尼日利亚和巴基斯坦。考克斯说,Meta“仍在努力以正确的方式在欧洲做到这一点”。欧洲的隐私规定更加严格,即将出台的人工智能法案也准备提出披露模型训练数据等要求。
每日经济新闻综合公开资料
每日经济新闻