理想汽车7月内全量推送无图NOA,发布全新自动驾驶技术架构
刘庆义 济南报道
2024年7月5日,理想汽车在2024智能驾驶夏季发布会宣布将于7月内向全量理想AD Max用户推送“全国都能开”的无图NOA,并将于7月内推送全自动AES(自动紧急转向)和全方位低速AEB(自动紧急制动)。同时,理想汽车发布了基于端到端模型、VLM视觉语言模型和世界模型的全新自动驾驶技术架构,并开启新架构的早鸟计划。
智能驾驶产品方面,无图NOA不再依赖高精地图或先验信息,在全国范围内的导航覆盖区域均可使用,并借助时空联合规划能力带来更丝滑的绕行体验。无图NOA也具备超远视距导航选路能力,在复杂路口依然可以顺畅通行。同时,无图NOA充分考虑用户心理安全边界,用分米级微操带来默契安心的智驾体验。此外,即将推送的AES功能可以实现不依赖人辅助扭力的全自动触发,规避更多高危事故风险。全方位低速AEB则再次拓展主动安全风险场景,有效减少低速挪车场景的高频剐蹭事故发生。
自动驾驶技术方面,新架构由端到端模型、VLM视觉语言模型和世界模型共同构成。端到端模型用于处理常规的驾驶行为,从传感器输入到行驶轨迹输出只经过一个模型,信息传递、推理计算和模型迭代更高效,驾驶行为更拟人。VLM视觉语言模型具备强大的逻辑思考能力,可以理解复杂路况、导航地图和交通规则,应对高难度的未知场景。同时,自动驾驶系统将在基于世界模型构建的虚拟环境中进行能力学习和测试。世界模型结合重建和生成两种路径,构建的测试场景既符合真实规律,也兼具优秀的泛化能力。
理想汽车产品部高级副总裁范皓宇表示:“理想汽车始终坚持和用户共同打磨产品体验,从今年5月推送首批千名体验用户,到6月将体验用户规模扩展至万人以上,我们已经在全国各地积累了超百万公里的无图NOA行驶里程。无图NOA全量推送后,24万名理想AD Max车主都将用上当前国内领先的智能驾驶产品,这是一项诚意满满的重磅升级。”
理想汽车智能驾驶研发副总裁郎咸朋表示:“从2021年启动全栈自研,到今天发布全新的自动驾驶技术架构,理想汽车的自动驾驶研发从未停止探索的脚步。我们结合端到端模型和VLM视觉语言模型,带来了业界首个在车端部署双系统的方案,也首次将VLM视觉语言模型成功部署在车端芯片上,这套业内领先的全新架构是自动驾驶领域里程碑式的技术突破。”
无图NOA四项能力提升,全国道路高效通行

将于7月内推送的无图NOA带来四项重大能力升级,全面提升用户体验。首先,得益于感知、理解和道路结构构建能力的全面提升,无图NOA摆脱了对先验信息的依赖。用户在全国范围内有导航覆盖的城市范围内均可使用NOA,甚至可以在更特殊的胡同窄路和乡村小路开启功能。
其次,基于高效的时空联合规划能力,车辆对道路障碍物的避让和绕行更加丝滑。时空联合规划实现了横纵向空间的同步规划,并通过持续预测自车与他车的空间交互关系,规划未来时间窗口内的所有可行驶轨迹。基于优质样本的学习,车辆可以快速筛选最优轨迹,果断而安全地执行绕行动作。
在复杂的城市路口,无图NOA的选路能力也得到显著提升。无图NOA采用BEV视觉模型融合导航匹配算法,实时感知变化的路沿、路面箭头标识和路口特征,并将车道结构和导航特征充分融合,有效解决了复杂路口难以结构化的问题,具备超远视距导航选路能力,路口通行更稳定。
同时,无图NOA重点考虑用户心理安全边界,用分米级的微操能力带来更加默契、安心的行车体验。通过激光雷达与视觉前融合的占用网络,车辆可以识别更大范围内的不规则障碍物,感知精度也更高,从而对其他交通参与者的行为实现更早、更准确的预判。得益于此,车辆能够与其他交通参与者保持合理距离,加减速时机也更加得当,有效提升用户行车时的安全感。
主动安全能力进阶,覆盖场景再拓展

在主动安全领域,理想汽车建立了完备的安全风险场景库,并根据出现频次和危险程度分类,持续提升风险场景覆盖度,即将在7月内为用户推送全自动AES和全方位低速AEB功能。
为了应对AEB也无法规避事故的物理极限场景,理想汽车推出了全自动触发的AES自动紧急转向功能。在车辆行驶速度较快时,留给主动安全系统的反应时间极短,部分情况下即使触发AEB,车辆全力制动仍无法及时刹停。此时,AES功能将被及时触发,无需人为参与转向操作,自动紧急转向,避让前方目标,有效避免极端场景下的事故发生。
全方位低速AEB则针对泊车和低速行车场景,提供了360度的主动安全防护。在复杂的地库停车环境中,车辆周围的立柱、行人和其他车辆等障碍物都增加了剐蹭风险。全方位低速AEB能够有效识别前向、后向和侧向的碰撞风险,及时紧急制动,为用户的日常用车带来更安心的体验。
自动驾驶技术突破创新,双系统更智能

理想汽车的自动驾驶全新技术架构受诺贝尔奖得主丹尼尔・卡尼曼的快慢系统理论启发,在自动驾驶领域模拟人类的思考和决策过程,形成更智能、更拟人的驾驶解决方案。
快系统,即系统1,善于处理简单任务,是人类基于经验和习惯形成的直觉,足以应对驾驶车辆时95%的常规场景。慢系统,即系统2,是人类通过更深入的理解与学习,形成的逻辑推理、复杂分析和计算能力,在驾驶车辆时用于解决复杂甚至未知的交通场景,占日常驾驶的约5%。系统1和系统2相互配合,分别确保大部分场景下的高效率和少数场景下的高上限,成为人类认知、理解世界并做出决策的基础。
理想汽车基于快慢系统系统理论形成了自动驾驶算法架构的原型。系统1由端到端模型实现,具备高效、快速响应的能力。端到端模型接收传感器输入,并直接输出行驶轨迹用于控制车辆。系统2由VLM视觉语言模型实现,其接收传感器输入后,经过逻辑思考,输出决策信息给到系统1。双系统构成的自动驾驶能力还将在云端利用世界模型进行训练和验证。
高效率的端到端模型
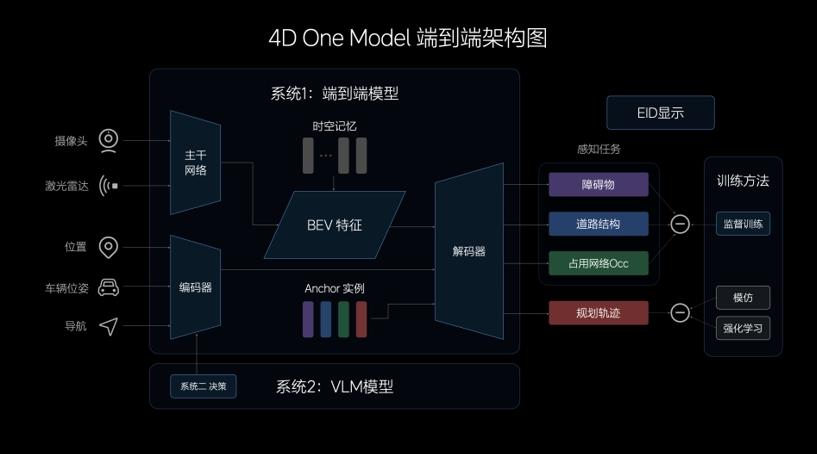
端到端模型的输入主要由摄像头和激光雷达构成,多传感器特征经过CNN主干网络的提取、融合,投影至BEV空间。为提升模型的表征能力,理想汽车还设计了记忆模块,兼具时间和空间维度的记忆能力。在模型的输入中,理想汽车还加入了车辆状态信息和导航信息,经过Transformer模型的编码,与BEV特征共同解码出动态障碍物、道路结构和通用障碍物,并规划出行车轨迹。
多任务输出在一体化的模型中得以实现,中间没有规则介入,因此端到端模型在信息传递、推理计算、模型迭代上均具有显著优势。在实际驾驶中,端到端模型展现出更强大的通用障碍物理解能力、超视距导航能力、道路结构理解能力,以及更拟人的路径规划能力。
高上限的VLM视觉语言模型
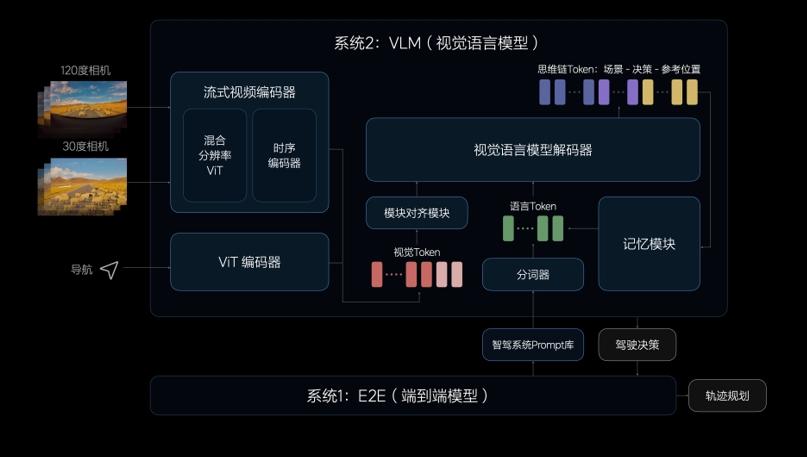
VLM视觉语言模型的算法架构由一个统一的Transformer模型组成,将Prompt(提示词)文本进行Tokenizer(分词器)编码,并将前视相机的图像和导航地图信息进行视觉信息编码,再通过图文对齐模块进行模态对齐,最终统一进行自回归推理,输出对环境的理解、驾驶决策和驾驶轨迹,传递给系统1辅助控制车辆。
理想汽车的VLM视觉语言模型参数量达到22亿,对物理世界的复杂交通环境具有强大的理解能力,即使面对首次经历的未知场景也能自如应对。VLM模型可以识别路面平整度、光线等环境信息,提示系统1控制车速,确保驾驶安全舒适。VLM模型也具备更强的导航地图理解能力,可以配合车机系统修正导航,预防驾驶时走错路线。同时,VLM模型可以理解公交车道、潮汐车道和分时段限行等复杂的交通规则,在驾驶中作出合理决策。
重建生成结合的世界模型
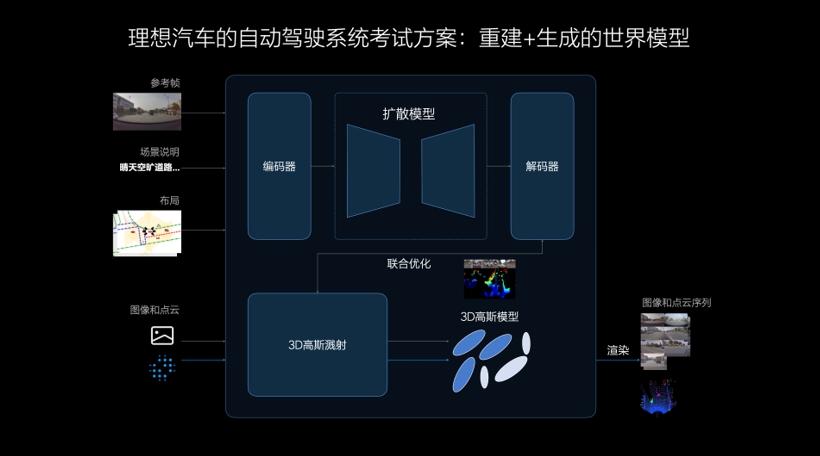
理想汽车的世界模型结合了重建和生成两种技术路径,将真实数据通过3DGS(3D高斯溅射)技术进行重建,并使用生成模型补充新视角。在场景重建时,其中的动静态要素将被分离,静态环境得到重建,动态物体则进行重建和新视角生成。再经过对场景的重新渲染,形成3D的物理世界,其中的动态资产可以被任意编辑和调整,实现场景的部分泛化。相比重建,生成模型具有更强的泛化能力,天气、光照、车流等条件均可被自定义改变,生成符合真实规律的新场景,用于评价自动驾驶系统在各种条件下的适应能力。
重建和生成两者结合所构建的场景为自动驾驶系统能力的学习和测试创造了更优秀的虚拟环境,使系统具备了高效闭环的迭代能力,确保系统的安全可靠。